浅谈高速公路收费数据的处理方法
时间:2013年01月11日 分类:推荐论文 次数:
摘要:高速公路营运过程中产生巨大的收费数据量,这些数据无论是对交通管理部门,还是对高速公路营运企业都是一笔十分宝贵的数据财富。在这些营运数据中反映了很多的信息,如何对这些海量数据进行科学的处理,找出规律,是道路管理部门亟待解决的问题。本文简单介绍了有效处理海量收费数据的一般方法。
关键词:高速公路 收费数据 处理方法
Abstract: highway operation process produce the huge charge data quantity, the data either to the transportation management department, or the highway operation enterprise is a very precious wealth of data. In these operations in a lot of data reflect information, how these mass data processing of science, and find out the law, is the way to the problems of the management department. This article simply introduces the effective process mass charge data of a general method.
Keywords: highway charge data processing method
一、引言
近年来我国高速公路发展迅速,江苏高速公路通车总里程已突破4000公里,通车总里程居全国第二,密度居全国第一。江苏省高速公路每月通行车辆数可达1000多万辆,道路营运产生的收费数据量是巨大的,江苏省高速公路联网收费系统储存了大量收费基础数据。在营运数据中,仅仅收费数据和轴重数据的记录,每月总量就可达到5000万条之多。这些数据充满了庞大的数据库,形成了浩瀚无垠的信息海洋。
在这些营运数据中反映了很多的信息,例如:轴重状况,车流量状况,车流量比例状况,每个路段车流负荷状况和每个收费站的收费人员工作状况等。这些信息对服务质量的提高,资源的有效使用,路面的有效保养都具有重要的参考意义。这些数据,无论是对交通管理部门来说,还是对高速公路营运企业来说,都是一笔十分宝贵的数据财富。如何对这些海量数据进行科学的处理,找出规律,对交通行业主管进行决策参考和管理公司指导营运管理,都具有很高的价值。在此本文就数据处理方法谈点体会。
二、处理方法
收费数据分析
根据【江苏省苏南高速公路联网收费暂行技术要求】、【江苏省苏北高速公路联网收费暂行技术要求】和【江苏省高速公路联网收费系统计重收费(数据部分)技术要求】的规定,高速公路联网收费原始数据分别存储在"入口车道原始过车记录表"、"出口车道原始过车记录表"和"轴重原始数据表"中。这3个表主要包含:入口数据、出口数据、路径数据、车辆数据、收费数据、管理数据、冗余数据。
在选用的关键数据中,除了可以直接看到的显式数据外,这些数据还隐含了一些其它数据内容。配合适当的方法以及相关数据,可以提取出这些隐含内容,主要包含:路段数据、地点数据、车型数据、超限数据、日期时间数据。
数据整理流程
数据整理流程从合并联网收费数据开始,到将预处理过的数据导入数据应用挖掘数据库为止,大致包括以下几个步骤:
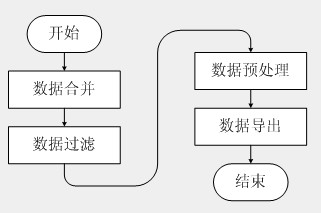
1. 数据合并
海量的收费数据分散放置在大量的数据表中,既不便于筛选和查询,也不便于统计和分析。在出口车道原始过车记录表包含了入口车道原始过车记录表中的入口数据和车辆分类数据,所缺的恰巧是不需要考虑的管理数据和冗余数据。因此只需要合并和处理出口车道原始过车记录表和轴重原始数据记录表的相关内容,即可满足数据挖掘的实际需要。
2. 数据过滤
因为收费数据中不仅包括进行数据应用处理时所需要的各种数据,例如:入口数据、出口数据、路径数据和车辆数据,而且还包括了不需要的其它数据:收费数据、管理数据和冗余数据。所以必须对合并后的收费数据分别进行多次过滤,逐步滤除不需要的数据。
3. 数据预处理
计算机在进行数据处理时,速度最快的是进行加减运算,其次是进行乘除运算,而幂运算、字符串运算和逻辑运算则计算速度很慢。
由于在进行数据应用处理时,许多数据应用处理都涉及到复杂的数学计算。在涉及到的计算方法中,不仅包括了四则运算,而且还包括了幂运算、字符串运算和逻辑运算。因此,不仅计算方法十分复杂,而且计算效率很难提高。
因为这些数学计算具有一定的共性,所以将其提取出来进行预处理,不仅可以减少数据应用处理的复杂程度,而且可以大大提高计算效率。
另外,从数据规定有效时段的角度来考虑,更应该对数据进行预处理。在进行数据预处理时,应该注意各个需要进行预处理的数据之间的先后关系。有部分数据是属于独立数据,例如:行驶里程数据、当量轴次数据,不论先处理或者后处理均无关系。也有一部分数据是属于有依赖关系的数据,例如:总轴限、超限限值、超限比例,必须按照特定的先后顺序处理,才能够保证得到正确的处理结果。否则,不仅可能得到错误的处理结果,甚至可能根本无法进行处理。
4. 数据导出
数据导出的操作方法和数据合并的操作方法类似,只是不存在多表对单表操作,而是单表对单表操作,所以在这里就不再冗述了。
数据整理注意要点
1. 批次大小
每期数据可以是一个月的数据,也可以是一年的数据,但是不能更多;每期数据的相关数据规定的有效时段必须相同,例如:2009年和2010年的数据不能同期处理;
当南北网数据分开处理并且每一次处理一个网一年的数据时,某些处理过程需要高达几十个小时,完成全部处理过程需要近二百个小时;但是,当每次处理一个月数据时,南北网数据在一天内即可全部完成处理;
这中间的差别是因为进行某些数据处理时,随着数据量的增长,数据处理量不是呈线性关系增长,而是呈指数关系增长;
出于保持数据完整性考虑,应该采用较大的数据处理批量;出于实际处理效率考虑,应该采用较小的数据处理批量;
兼顾两者,通盘考虑,建议南北网数据分别处理,每次处理一个季度的数据为宜。
2. 处理位置
在存放原始数据的数据库中进行处理,不仅可以得到最好的数据处理效果,因为不需要传输数据,还可以节省大量数据传输时间;
具体操作时可以利用SQL脚本自动生成临时数据表,完成数据整理和数据导出后,再删除临时数据表释放存储空间;
以每次处理一个季度的数据为例,占用存储空间只有几个GB,加上处理过程中占用的日志空间,也不会超过20个GB;为了减少日志占用的存储空间,尽可能不要将处理脚本一次性全部提交,而是人为将其分割成几个部分分次提交。
3. 处理效率
为了提高处理效率,除了必须按先后顺序进行的处理外,应该尽可能将处理条件相同或者接近的数据处理放在一个处理过程中完成,例如:车辆轴型和总轴限处理过程;
在用到数据检索、数据匹配操作时,应该尽可能建立索引(不一定是建立主关键词,有时虽然不能建立主关键词,但是可以建立索引。)后,再进行数据处理,例如:行驶里程数据预检索过程;
应该尽早检查错误数据,并且及时加以剔除,以防止数据处理过程中断;因为数据处理过程中断后,不仅前面的处理工作全部浪费,而且数据库回滚恢复原状还需要占用大量的时间;
只有通过各种方法配合,通盘综合考虑,才可能有效的提高总处理效率。
三、结束语
高速公路联网营运在我国日渐广泛,软件技术和硬件设施的发展也与世界先进水平相距不远。和银行、电信、地质、保险、零售等数据挖掘技术应用广泛的行业相比,高速公路数据应用处理的方法和深度还有一定的差距,这与高速公路信息技术高速发展不相匹配。高速公路行业的主管部门希望在行政决策和行业管理上得到更充分、更深入、更有针对性的相关数据支持;同样高速公路管理公司和营运企业,也希望在改善服务质量、提高管理水平、优化资源配置等方面,得到更有效的数据支持。利用合理有效的数据处理手段能够总结提炼出对高速公路运营管理有益的规律和手段,能够完善高速公路的管理,有效地提高高速公路的管理质量和服务质量,为高速公路建设进一步向信息化、智能化方向发展打好基础。
参考文献:
[1] 交通部.联网收费技术要求[S]. 北京:人民交通出版社
[2] 江苏省苏南高速公路联网收费暂行技术要求
[3] 江苏省苏北高速公路联网收费暂行技术要求
[4] 江苏省高速公路联网收费系统计重收费(数据部分)技术要求
[5] 刘伟明等.高速公路收费系统理论与方法[M]. 北京:人民交通出版社
SCI论文
- 2023-08-01sci四区发论文最容易吗
- 2023-05-10英文论文的检索号是什么
- 2024-10-23SCI期刊要自己推荐审稿人 推荐谁
SSCI论文
- 2024-02-02学霸笔记:超级好用的ssci论文发
- 2024-03-22SSCI四区的文学期刊
- 2023-03-08全球经济趋势分析论文发表ssci期
EI论文
- 2022-11-11ei会议论文会拒稿吗
- 2022-08-12发表scopus论文的步骤
- 2023-05-31纺织类的ei期刊(3-5本)
SCOPUS
- 2023-04-21论文被scopus成功录用需要多长时
- 2023-03-14scopus期刊收研究生论文吗
- 2023-02-20scopus检索与ei哪个好
翻译润色
- 2023-05-06基因测序文章怎么翻译润色
- 2024-08-17国际中文期刊评职称承认吗
- 2022-05-07sci论文润色更容易录用吗
期刊知识
- 2022-03-08火电厂论文外文翻译有什么服务
- 2021-01-16高钾血症论文发表期刊
- 2020-02-07sci期刊发表的论文都可以被web o
发表指导
- 2024-08-17氧菌论文可以投稿的期刊
- 2021-08-07电熔炉相关论文文献看哪些
- 2018-04-04经济学动态发表论文审稿周期多久