�������ϱ�ע��ȫ��������ƪ�¼��¼���ȡ
ʱ�䣺2020��03��11�� ���ࣺ�������� ������
����ժҪ���¼���ȡ���������ǴӺ������ı��п��١�ȷ�ػ�ȡ����Ȥ���¼�֪ʶ��Ȼ����Ŀǰ�¼���ȡ���о���Ҫ�����ڴӵ�һ�����г�ȡ�¼�.�����¼����ɵĸ����Ժ����Ա����Ķ����ԣ���������¶���������������һ���¼�����ˣ���ƪ���г�ȡ�������Ľṹ���¼���Ϣ���Եø��м�ֵ�����塣�����������û���ע�������Ƶ����б�עģ�����ϳ�ȡ���Ӽ��¼��Ĵ����ʺ�ʵ�壬���������ʵ���ȡ���¼�ʶ����ȣ����ϱ�ע�ķ�����Fֵ��������1���ٷֵ㡣Ȼ�����ö���֪���ж�ʵ�����¼��а��ݵĽ�ɫ������ھ��Ӽ��¼���ȡ�Ļ����ϣ������������Թ滮�ķ���������ȫ������.�ںϾ��Ӽ��¼���Ϣ��ʵ��ƪ�¼��¼���ȡ.�����ģ�����.���ֻ���ȫ��������ƪ�¼��¼���ȡ��Fֵ��������3���ٷֵ㡣
�����ؼ��ʣ�ƪ�¼��¼���ȡ;���ϱ�ע;ȫ������
����o����
����������ᣬ�������ѳ�Ϊ�����ճ������в��ɻ�ȱ��һ���֣���Ϊ���ǵ����ѧϰ���������������ͬʱ���������к����ķǽṹ���ı�Ҳ���û�������Ϣ���������š�������������ķǽṹ���ı����ݣ���ΰ����������Ⲣ���ٻ�ȡ�ı��е�֪ʶ���Ե���Ϊ��Ҫ������Ϣ��ȡ�������������Ϊ�˽��������⡣��Ϊ��Ȼ���Դ���(NaturalLanguageProcessing,NLP)�����еĹؼ�������Ϣ��ȡ��֪ʶ��ȡ�а�������Ҫ�Ľ�ɫ��Grishman�ȢŽ���Ϣ��ȡ����Ϊ������Ȼ�����ı��г�ȡָ�����͵�ʵ�塢��ϵ���¼�����ʵ��Ϣ�����γɽṹ������������ı�����������������ǽṹ���ı����¼���ȡ����Ϣ��ȡ�����еĹؼ��������Ҫ���о�����(�����ʵ���ȡ����ϵ��ȡ��)����ҪӦ�����¼�֪ʶͼ�Ĺ������¼���Ϣ��ȡ����������Ȼ������������
�����¼��Ǹ����ӵĸ���ڲ�ͬ�о������в�ͬ�Ķ��塣�¼���ȡ���������Ӱ�������������----�Զ����ݳ�ȡ(AutomaticContentExtrac-non,ACE®)������齫�¼�����Ϊ���¼��Ƿ�����ij���ض�ʱ���ʱ��Ρ�ij���ض�����Χ�ڣ���һ��������ɫ�����һ�������������ɵ������״̬�ĸı䡣�¼��е����������嶨�����£�ʵ��(entity)���û�����Ȥ���������.ͨ����һ������(���磬“����”);�¼�������(eventtrigger):�����¼��ĺ��Ĵʣ�ͨ���Ƕ��ʻ�������(���磬“ɥ��”��“����”);�¼�Ԫ�ؽ�ɫ(eventargument):ʵ�����¼��������ݵĽ�ɫ•���¼��IJ�����;�¼�����(eventmention):�����¼���һ�仰����һ���ֶΣ�ͨ������������ʺ��¼�Ԫ��;�¼����(eventtype)���¼������ʺ��¼���ɫ��ͬ�������¼������
�����¼������ʺ�ʵ�����������������ǣ����»��ߵ��ֶδ���ʵ�弰�����(���磬“10��31��”•ʱ��)���Ӵ��ֶδ��������ʼ����¼����(“ɥ��”������)���������Ӵ����ʺ�ʵ��.���������ִ���ʵ���ڸ��¼��������ݵĽ�ɫ���ڱ�ʵ���У�“ɥ��”����һ�������¼���T0��31��”“���������ʻ���”“82��”�ڸ��¼��зֱ����ʱ�䡢�ص���ܺ��ߵ��¼���ɫ.�Ӷ����һ���������¼�����ʵ��“�¼��º���”�ڸ��¼��в������κν�ɫ����ACE���¼��Ķ��弰ͼ1ʵ���ɵã��¼������Ҫ����Ҫ�����¼��ķ���ʱ�估�ص㣬�¼��IJ����ɫ�Լ���֮��صĶ�����״̬(������)������ʵ������.ÿ�춼�и�ʽ�����IJ�ͬ��������ͬ���͡���ͬ���ȵ��¼���������Ϣ������������ͬʱҲ���¼���ȡ��������Ѷȡ�
������Ϊ��Ȼ���Դ����о�����ս�������¼���ȡ��Ҫ�о���δӷǽṹ�����ı���Ϣ�г�ȡ���û�����Ȥ���¼������Խṹ������ʽ���ֳ�����Ŀǰ�¼���ȡ���о���Ҫ�����������������ϣ��¼�ʶ����¼�Ԫ��ʶ���¼�ʶ��ʶ���ı��е����¼��������������¼�ʵ���������ݵ�ǰ�����ʺ���������Ϣ�жϵ�ǰ������Ԥ�����¼����͡��¼�Ԫ��ʶ����ij�䱻�ж�Ϊ�ض��¼����͵��¼����������жϾ���ʵ����¼�������֮��Ĺ�ϵ������Ĺ�ϵ��Ϊʵ���ڸ��¼��������ݵĽ�ɫ�������¼���ȡ������Ҫ����Ծ��Ӽ���ģ������е��¼���ȡ��ܰ����ı����ȿɷ�Ϊ���Ӽ��¼���ȡ��ƪ�¼��¼���ȡ�����Ӽ��¼���ȡ���㼯����ʶ�������ÿ���ʿ����ἰ�ĵ����¼�.�Լ��жϾ���ʵ���ڸ��¼��а��ݵĽ�ɫ����Ȼ���Ӽ���ȡ���ǵ��¼������㹻ͨ��(ACE2005�ж�����33���¼�)���������ܽ��ĵ�������˵�����Ӽ���ȡ����̫ϸ�ˡ���ʵ�����У�һƪ�ĵ�ͨ������һ�����߶���¼�����Щ�¼������������Ҫ�Ը�����ͬ.��ͬһ�¼�Ҳ���ܻ����ĵ��б�����ἰ��
����ƪ�¼��¼���ȡ���ı�����������Ҫ�¼�Ϊ���ģ��ü�ࡢ�ṹ������ʽ���ָ��û���������ʵ������ֱ�������û�Ҳ�������Ե������ԣ��������û����ٻ�ȡ�ĵ��е��¼����ݡ��ص��ʱ�䣬������Ҫͨ��ȫ�ġ��ѵ����ڣ�ƪ���¼���ȡ��Ҫ�������ľ��Ӽ���ȡ����Լ���ͬ�¼���ͬ�¼�����֮���¼�Ԫ�ص��ںϣ������������䣺��1�����ݰµ���������֯��ͳ�ƣ��ڰ�����˹ɽ��ɽ�³�ʧ��Ҿ�����155���˿�ɥ������2���µ���һ����ѩʤ�صĵ�ɽ�³�11���ڰ�����˹ɽ���������³�ʧ��Ҿ�.�ܺ����а�����1999������Ů�ӻ�ʽ��ѩ�ھ�ʩ���ء���1����2������ͬһ�����¼��IJ�ͬ���ӣ��ֲ���ԭ�ĵ��в�ͬ�Ķ��䵱�С���1�а����������¼��������������¹���Դ����2�а����¼�������ʱ��͵ص㡣�¼�������1����2�еĽṹ���¼���Ϣ��Ҫ�ںϲ��ܵõ�������ƪ�¼��¼���Ϣ��ƪ�¼��¼���ȡ�����ھ��Ӽ���ȡ����Ϳ���ӵ��¼�Ԫ���ںϡ�
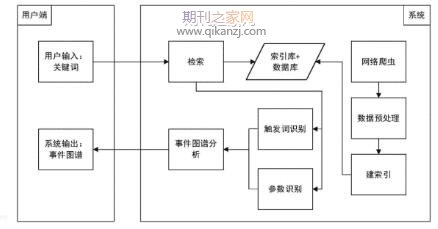
���������۳�����Ϊ�˻�ȡƪ�¼��¼��Ľṹ����Ϣ����Ҫ���Ӽ��¼���ȡ������¼���ָ��ϵ�жϡ�Ŀǰ���ƪ���¼���ȡ�о����٣���û��ͳһ��ͳ��ѧģ���ܴ�ƪ����ֱ�ӳ�ȡ��ƪ�µ��¼���Ϣ���෴�����Ӽ��¼���ȡ���о��������죬�ھ��Ӽ���ȡ����Ļ����Ͻ���ȫ���ƶ����ƪ���¼���ȡ�����������DZ����о��ķ����IJ��ùܵ�(Pipeline)�ķ�����ƪ�¼���ȡ�����Ϊ3�������⣺���������б�עģ�ͶԾ��ӽ���ʵ����¼������ϱ�ע;�ڲ��ö���֪�����¼������е�ʵ����з��࣬�ж�ʵ���ڸ��¼��������ݵĽ�ɫ;�ۻ����������Թ滮��ȫ���������õ�ƪ�¼��ṹ���¼���Ϣ������������ͼ�в�������ע�����е�������Ϣ���ⲿ��Դ��
�����ܵ���˵�����ĵĹ�����������3�㣺(1)�����ʵ����¼������ϱ�עģ��.��ģ�Ϳ��Ը��õ������������е�ʵ����¼����������ϵ��(2)��������������Թ滮�ķ�������ȫ�������õ�ƪ���¼���ȡ�����(3)��ACE2005���������Ͻ���ʵ�飬ʵ������֤��ģ�͵���Ч�ԡ�
����1����
�������������Ѿ�֤���������緽������Ȼ���Դ����������Ч�ԡ�Zeng��Chen�Ȣ����Ƚ����ѧϰ�ķ���Ӧ���ڹ�ϵ��ȡ���¼���ȡ�У���ȡ���˺ܺõ�Ч��������ڴ�ͳ������ʾ�ķ�ʽ�������罫������(Wordembedding)��Ϊ���룬�����˴�ͳ������ȡ���̹����������Ա�ע���䷨��������Ȼ���Դ������ߡ��ڱ����У����ǽ����ܱ���ƪ�¼��¼���ȡ��ȡ�ķ�������Ҫ����ʵ����¼����ϱ�ע���¼�Ԫ��ʶ��ȫ��������
����1.1ʵ����¼����ϱ�ע
����ʵ����¼��ǽ��ܹ����ģ����ߵı�ʾ������������е��¼���ȡͨ������ʵ����¼��ֱ�ģ����Ŀǰ�¼���ȡ������.�о���һ�㽫�¼���ȡ��Ϊ3������ʵ��ʶ�������ⲿ�����ߵ�һģ�ͳ�ȡ���е�ʵ��;���¼�ʶ�𣺳�ȡ���еĴ����ʲ��ж��¼�����;��Ԫ�ط��ࣺ�ж�ʵ�����¼��а��ݵĽ�ɫ��ʵ��ʶ����¼�ʶ��ֿ������dz��õļ����ֶΣ��������ʵ����¼�������֮��������Ĺ�ϵ��
�������磬������“�°����뿪����ӭ���µ���ս”�У�“�뿪”��Ϊ�����ʣ�������һ����ְ�����¼����������������¼���ֻ����“�뿪”һ�ʣ���������壬������֪��������ʵ�弰������(“������֯����”;“�°���������”)�������ж�“�뿪”������ְ�¼�;�෴������֪“�뿪”������ְ�¼��������ж�“��”��ʵ���������֯���������ǵ���λ�á������Ч����ʵ����¼������ʵ������ϵ���DZ���������ϱ�עģ�͵ij����㡣
�������IJ������б�עģ�ʹӾ������ϱ�עʵ��ʹ����ʣ�ͬʱ�ж����ǵ���𣬲������ȡ�����Ϊ�¼�Ԫ�ر�ע�����롣Ϊ�˸��õؽ�ģ�����ĵĹ�����ϵ.���ǽ���ע��������(self-attention)M�ӵ�ģ���С�Ŀǰ�кܶ�ͳ��ѧϰ�������Զ������ı��еĴʽ���ʶ���࣬�����ô���Ϊ������Ҫ�Ƚ����ⲿ�ִʹ���.�����б�ע�����ܹ��ܺõؽ�����Ĵʼ���������⡣����Ȼ���Դ����У��ܶ�������ⶼ���������б�עģ�ͽ�����������ķִʡ����Ա�ע�Լ�����ʵ��ʶ��ȡ����б�ע�����ܲ���ʵı߽磬ͬʱҲ�����жϵ�ǰ�ʵĹ������
������ͬ���ı����࣬���б�עģ�ͽ�����ľ��ӿ���һ�����У������һ���ȳ��ķ������У�ÿ�����Ŷ�Ӧ�ض��ĺ��塣�������������б�עģ�������е�ÿ���ַ�����BIO�ı�ǩ��B��ʾ�ֶο�ʼ(beginning),1��ʾ�ֶ��м�(inside),0��ʾ�����ֶ�(outside),��ǩ�������type��ʾ�ֶεķ�����������.B-PER��ʾ��������ʼ�ַ���I-Attack��ʾ���������¼��ʵ��м��ֶΡ��������ѧϰ����Ȼ���Դ����е�Ӧ���������죬����������ķ�����ʾ�ַ��������ܸ��õز������Լ������ĵ���Ϣ��
�������������У�Ŀǰ����������������ѭ��������(RecurrentNeuralNetworks,RNN)�;���������(ConventionalNeuralNetworks,CNN)�����֮�£�RNN��CNN���ʺϸ����н��н�ģ����ΪRNN��������е�ǰʱ�̵����룬Ҳ��ǰһʱ�̵������������ʹ������ͨ��ѭ���������ӿ���ǰ�����Ϣ�����һ��߱������Ե�����������������RNN�����е����еĽ�ģ��NLP�г��õ��ֶΡ��������ڼ�������(LongShort-TermMemory,LSTM)�ܽ���ȥ�ͽ��������п��ǽ���.ʹ����������Ϣ��ֱ�����Ϊ����LSTM��������������(ConditionalRandomFields,CRF)�ܸ���ؿ����������ӵľֲ����������Լ�Ȩ��ϣ��������ϸ��ʣ��Ż����������С�ͬʱ.���ǽ���ע�������Ƽӵ�ģ���У���ҪĿ����ѧϰ�����ڲ��ַ�֮���������ϵ��������ӵ��ڲ��ṹ��������Ϣ��
����1.2�¼�Ԫ��ʶ��
�����ĵ���ÿ�����Ӿ���������ʵ����¼����ϱ�ע�ɻ�þ��е�ʵ�弰��ʵ�����ͺ��¼������ʼ����¼����͡�Ϊ�õ����Ӽ����¼��ṹ����Ϣ����Ҫ��һ����עʵ�����¼��а��ݵĽ�ɫ����ʵ��ʹ�����֮��Ĺ�ϵ(��Ů�ڣ��б�ʵ��“155���˿�”��“����”�¼������а�����“�ܺ���”�Ľ�ɫ)��Ϊ�˳������ʵ�������;����е��¼���Ϣ����������һ������֪��ʵ��ʵ��ķ���Ӷ�ʵ���¼�Ԫ��ʶ�������������������ʡ����������ʵ�塢ʵ�����ʵ��ʹ�����֮���λ����Ϣ�Լ���ǰ����ͨ��LSTM����������ʾ��
����1.3ȫ������
�������ĵ��ı��У���Ҫ���¼�ͨ���ᱻ����ἰ����ͬһ�¼����ж���¼������������������Ӽ��¼���ȡ���ɻ��ƪ���е�һϵ�нṹ���¼���Ϣ��Ϊ���ƪ�¼����¼���Ϣ����Ҫ�ж϶���¼������Ƿ�ָ��ͬһ�¼����Ӷ��õ��������¼���Ϣ���¼�������1����2�ֱ�ͨ��“ɥ��”��“�ܺ�”����“����”�¼����ͣ�ͨ���ı����������Ƴ̶ȿ��Խ�һ���ж���1����2ָ����ͬһ�¼����Ӷ������ߵ��¼�Ԫ�ؽ����ںϵõ�ƪ�¼����¼��ṹ����Ϣ��Ϊ�˳�������ı���Ϣ�����¼���ָ���жϣ����IJ����������Թ滮�ķ�������ȫ������������ȡ���õ��¼���ָ�ж���Ϊ�Ż�Ŀ�꣬���ı����ƶ���Ϊ�Ż�Ŀ�����Ҫϵ����������Լ���£��õ�ƪ�¼��¼���ȡ�����Ž����
����2ģ��
����������Ҫ���������������õ�ģ�ͣ�����������ע�������Ƶ�ʵ���¼����ϱ�עģ�͡����ڸ�֪�����¼�Ԫ��ʶ��ģ�ͺͻ����������Թ滮��ȫ��������
����3ʵ��
����3.1����
������������ACE���ⷢ���Ĺ�������ACE2005�е�����������Ϊʵ�����ݼ������ݼ��б�ע��ʵ����������PER(Person,����)��ORG(Organization,��֯����)��GPE(Geo-PoliticalEntity,���λ����ĵ�������)��LOC(Location������λ��)��FAC(Facility,������ʩ�ij���),VEH(Vehicle,���乤��),WEA(Weapon,����)�Լ�VALUE(ֵ)��TIMECʱ��)��ACE2005��Ԥ����33���¼������ÿ���¼�����ɲ�ͬ���¼���ɫ���ɡ����IJ���Chen��Ji�Ƚ������ݵĻ���ʱ,����569/64/64/ƪ�ĵ��ֱ�����ѵ����/���Լ�/��֤��������P(Precision,��ȷ��)��R(Recall,�ٻ���)����ֵ���۾��Ӽ���ʵ���ȡ���¼�ʶ�����ܡ�����Reichart�Ȣ˲��õ�ƪ�¼��¼���ȡ���۷�ʽ������ÿƪ�ĵ�����ѧϰ���Ľṹ���¼���Ϣ�ͱ��������ƥ�䣬Ȼ������P��R��F,����ƪ�¼��¼���ȡ���ܵ����⡣
����3.2����
����ģ�͵�һЩʵ��ϸ�����£������embeddingΪ100ά�Ĵ���������ͨ����ά���ٿ��������Ͻ���Ԥѵ���õ��ġ�LSTM����ά��Ϊ200,batch�趨Ϊ50,ѧϰ��Ϊ0.000l,droupoutΪ0.5.���ղ���Adam��Ϊ�Ż�����
����4����о�
������ǰ�¼���ȡ�����о������ɷ�Ϊ�����ࣺ����ģʽƥ��ͻ���ͳ��ģ�͡�ģʽƥ��ķ������ض�������ȡ���Ϻõľ�ȷ�ȣ����͵Ļ���ģʽƥ����¼���ȡϵͳ�У�ExDisco[l0]��FSA^�����÷�����Ҫ�����˹�����ģ��д�����������Բֻ������С��ģ���ض�������ͳ��ѧϰ�ķ�����������ѡȡ���ֿɷ�Ϊ���ࣺ���ڴ�ͳ����ѡȡ�ͻ����������Զ�ѧϰ��������ͳ������ȡ��Ҫͨ����Ȼ���Դ�������ȡ������Ч�Ĵʻ㡢�䷨�������������Ȼ�����ô�ͳ����ģ��(���磬���ģ�ͺ�֧��������ģ��)���з���"“�����������ѧϰ֤��������NLP�е���Ч��,Chen�Ȣ����Ƚ�CNNӦ�õ��¼���ȡ�У��������˾�����Ϣ����ģʵ��ʹ����ʵ�λ�ù�ϵ;Nguyen�ȡ������һ�ֻ���RNN��ģ�ͽ����¼�ʶ��ͽ�ɫ���������ѧϰ��
�����������ȱ����ƽ������⣬Liu�Ƚ����ⲿ������Դ�����¼�ʶ��;Chen������Զ�̼ල�ķ�������ѵ������������¼���ȡ����;Yang�ȡ�������ƪ����Ϣ�����¼���ʵ������ϳ�ȡ���������Ϊ3�������⣺ѧϰ�¼��ڲ��ṹ��ѧϰ�¼����¼���ϵ��ѧϰʵ���ȡ;Uu�Ȣš�����˫����Դ����¼���ȡ�����ܡ���Щ������Ӣ���¼���ȡ���ݼ���ȡ���˺ܺõ�Ч���������¼���ȡ���棬�ʼ��IJ�ƥ����������Ӱ���˺�����Ϣ��ȡ�дʼ�ģ�͵����ܡ�Ϊ�˽��������,Chen��Ji�Ȣ�����˻����������ַ���BI()��ע;Li�ȡ��Ӷ��������Ĵ����ʵ��˹�ģ�壬��Щ�������߶��������˹�������ģ������������ı����ȿ���Ŀǰ�¼���ȡ������о���Ҫ��Ծ��Ӽ���ij�ȡ.��ʶ����д����ʣ����ж�ʵ�����¼��������ݵĽ�ɫ������ʵ������ı��������ƪ�µ���ʽ���֣��û������ĵ��Ǵ�ƪ���л�ý�������¼�֪ʶ��
����������¼���ȡϵͳFRUMPY]�����¼�ģ��ƥ��ķ�������ƪ���¼���ȡ��Huang�Ȳ��û���ģʽ����ķ�������ƪ�³�ȡ�������������⣺�ٽ�ɫ�����;�ھ��ӹ���ģ�͡�Yang��[�A���û��ھ��ӳ�ȡ����Լ��ı������������¼�������������������Ԫ�ز�����Եõ�ƪ���¼��ṹ����Ϣ�ķ����������Ľ����¼���ȡ���ݼ���ȡ�ò�����Ч�����ܵ���˵��Ŀǰƪ���¼���ȡ���о���Ҫ�������ض������߶������˹��������ƹ㵽�µ��������Ӽ��¼���ȡ����Ӧ���ڸ��㷺���������ɵ��������̫ϸ�����ṩ�õ��ĵ����¼���Ϣ��
����5�ܽ��չ��
���������������¼���ȡ����֪ʶ��ȡ����Ҫ�ԣ��������˾��Ӽ��¼���ȡ��ƪ�¼��¼���ȡ�IJ��졣��Ⱦ��Ӽ��¼���ȡ��ϸ���Ƚ����ƪ�¼��¼���ȡ�Ľ���ܷ�ӳ���������¼���Ϣ�����и��õ���ʵ�����ʵ�ü�ֵ��Ϊ�˴��ı��л�ȡƪ�¼��¼���Ϣ�����IJ������ѧϰ�ķ�����ȡ���Ӽ��¼���Ϣ����ģ������������ɣ��������б�ע���¼�ʵ�����ϳ�ȡ�ͻ��ڶ���֪�����¼�Ԫ��ʶ���ھ��Ӽ��¼���ȡ�����ϣ���ȡ�������Թ滮����ȫ���ƶϵõ�ƪ�¼��¼��ṹ����Ϣ��������ACE2005���ݼ��ϵ�ʵ����֤���˷�������Ч�ԡ�Ȼ��������Pipeline�ķ������ɱ���ػ�������Ĵ��ݡ�������ö˵��˵�ģ��.��ƪ���ı���ֱ�ӳ�ȡ���¼��ṹ����Ϣ������ƪ�¼��¼���ȡ�������ܣ�����һ����Ҫ�о���������ݡ�
����������ķ��ģ�����������Ʒ��������е�Ӧ���о�
����ժҪ��21���������羭�ô�չ��ʱ�����ǿ�ѧ�������Ӿ�������ʱ�����Ǽ���ı�����˼ά��ʽ���������ʱ�����Ǵ�������δ���Ͳ��ϱ�չ����ʱ�������ż�����������ռ������ǿ�ʼ���ճ����������������������������Լ���ɹ��������������������Ч�ʣ������Ա�֤�����������Դﵽ�°빦����Ч�������ּ����������������ڼ���������������½����˿�ǰ��չʱ�ڡ�
SCI�ڿ�Ŀ¼
���ź����ڿ�Ŀ¼
SCI����
- 2024-10-23SCI�ڿ�Ҫ�Լ��Ƽ������ �Ƽ�˭
- 2023-08-01sci������������������
- 2023-05-10Ӣ�����ĵļ�������ʲô
SSCI����
- 2024-03-22SSCI��������ѧ�ڿ�
- 2024-02-02ѧ�Աʼǣ��������õ�ssci���ķ�
- 2023-03-08ȫ�����Ʒ������ķ���ssci��
EI����
- 2022-08-12����scopus���ĵIJ���
- 2023-05-31��֯���ei�ڿ�(3-5��)
- 2022-11-11ei�������Ļ�ܸ���
SCOPUS
- 2023-04-21���ı�scopus�ɹ�¼����Ҫ�ʱ
- 2023-03-14scopus�ڿ����о���������
- 2023-02-20scopus������ei�ĸ���
������ɫ
- 2024-08-17���������ڿ���ְ�Ƴ�����
- 2023-05-06�������������ô������ɫ
- 2022-05-07sci������ɫ������¼����
�ڿ�֪ʶ
- 2022-03-08��糧�������ķ�����ʲô����
- 2020-02-07sci�ڿ����������Ķ����Ա�web o
- 2021-01-16��Ѫ֢���ķ����ڿ�
����ָ��
- 2024-08-17�������Ŀ���Ͷ����ڿ�
- 2018-04-04����ѧ��̬��������������ڶ��
- 2021-08-07����¯�������������Щ